Security Data Pipelines
Write data the right way, powered by Query Federated Search.
Overview
Sometimes you just need to move data. Security teams use telemetry from dozens of sources. When it’s time to store, search, or analyze that data, things break down. SIEM costs explode. Custom pipelines get brittle. And most so-called “data platforms” just add complexity.
Query Security Data Pipelines are powered by the same engine that powers Query Federated Search, with the main benefit of providing in-situ normalization and standardization of disparate and federated data sources into the Open Cybersecurity Schema Framework (OCSF) data model. The OCSF data model provides translation of common security key-value pairs into easy to find sources to power machine learning feature extraction, fine-tuning LLM FMs, performing analytics, or just searching and visualizing your security data.
Query Security Data Pipelines are architecturally simplistic. You choose a Source which is any Static Schema Connector, except Cyber Threat Intelligence & OSINT (besides MISP) along with a Destination which include Amazon S3, Azure Blob & ADLSv2, Google Cloud Storage, Splunk HEC, and the Cribl Stream HTTP Bulk API. You choose a single Source and one or more Destinations per Pipeline which define the schedule and in future releases you'll be able to choose specific OCSF events, specific Attributes, as well as perform pre-processing tasks by filtering on specific values.
Use Cases
While Query Federated Search provides connectors to support ad-hoc analytics, detections, search, and visualizations of your data from the source - there are times where moving to more durable storage makes sense. Query never stores or otherwise duplicates your data and supports many APIs that are not always ideal for ad-hoc search due to rate limiting, smaller retention windows, and response times. The following use cases are supported by Query Security Data Pipelines
- Longer term retention of downstream data, especially for platforms with limited retention windows such as Entra ID, Google Workspace, JumpCloud SSO, and otherwise.
- Moving data in a performant way to object storage, SIEMs, and data lakes for more performant and complex search capabilities.
- Search Amazon S3 Destinations with AWS Glue + Amazon Athena Connector
- Search Azure Blob Destinations with Azure Data Explorer (ADX) Connector
- Search Google Cloud Storage Destinations with Google BigQuery Connector
- Search Cribl Stream - HTTP Destinations by pipelining data to Cribl Lake and using the Cribl Search Connector
- Searching Splunk HEC Destinations with the Splunk Connector
- Taking advantage of OCSF-formatted data for MLOps and AIOps.
- Visualizing data in durable object storage with BI tools such as Qlik, QuickSight, PowerBI, and Looker Studio.
Supported Sources
For the purpose of Query Security Data Pipelines, a Static Schema Connector is synonymous with a Source. The following categories of sources are supported today.
All Sources are supported by Query Security Data Pipelines except for the following Connectors due to lack of broad query capability:
- WHOIS XML API
- VirusTotal
- AlienVault
- CISA KEV | MITRE CVE Database
- Shodan
- Tego
- ip-api Geolocation API
Supported Destinations
Destinations are purpose-built write-only sources supported by Query Security Data Pipelines. Each Destination is written into the right way including but not limited to:
- Proper partitioning and/or clustering, in accordance with the Hive specification
- Data is written in ZStandard (ZSTD) or Snappy compressed Apache Parquet, except for sources that expect JSON, it is written in GZIP-compressed JSON (not JSON-LD or JSON-ND garbage).
- Data is written in batches that match the maximum acceptable throughput of the destination.
- Data is written in OCSF, based on Query mappings for our Connectors (or your mappings for dynamic Connectors).
If you need another Destination or output parameter supported, please reach out to [email protected] referencing any Pipeline Destination and parameter variation you want us to support. Snowflake Iceberg Tables, Azure Data Explorer, and Google BigQuery are on our immediate roadmap.
- Amazon S3
- Azure Blob Storage (and ADLSv2)
- Cribl Stream - HTTP Sources
- Google Cloud Storage
- Splunk HTTP Event Collector (HEC)
Configuring a Pipeline
Configuring a Pipeline is a simple action, ensure that you have configured a Destination from the previous section before doing so.
Important Note on UX
Query Security Data Pipelines are currently in Public Preview, and the UX is subject to change.
-
In the Query Console, navigate to the Pipelines section denoted by a delivery truck symbol and at the top of the screen, select + New Pipeline to enter the Pipeline creation wizard as shown below.
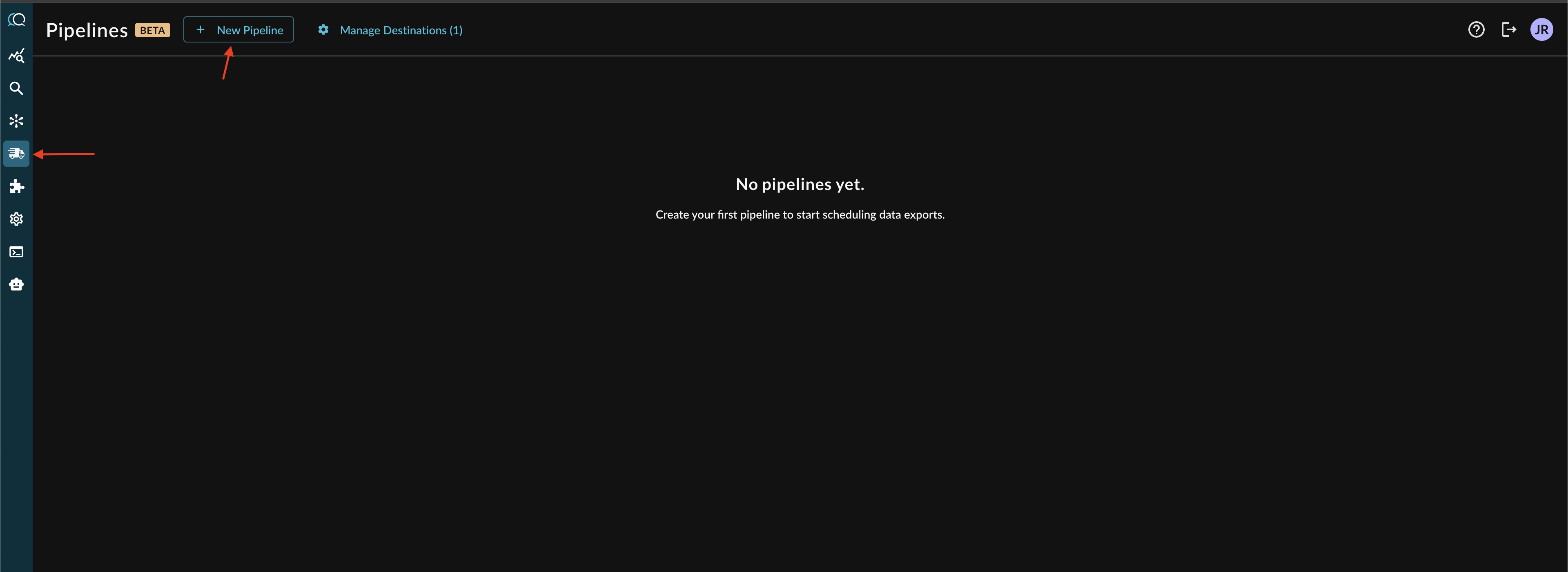
-
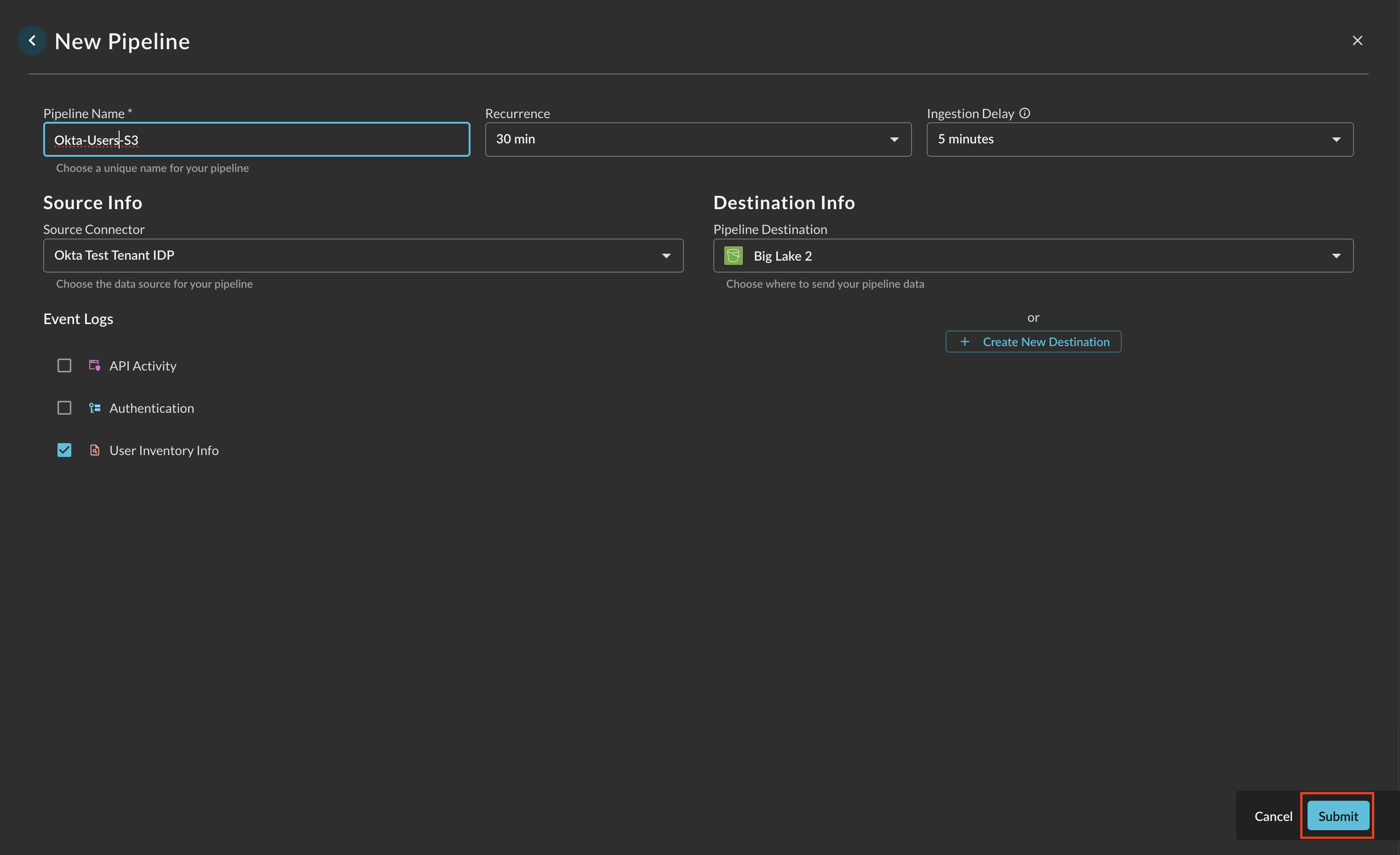
Provide the following parameters to the Pipeline creation wizard.
- Pipeline Name: The human readable name of your Pipeline. Use this to provide descriptive names of sources, event types, and destinations, or otherwise.
- Recurrence: How often you want the pipeline to run. Currently you can choose 30 minutes, 60 minutes, or 24 hours.
- Ingestion Delay: Shifts the start and end date range of the job's query back by a certain amount of time. This is useful when source systems have a delay between event occurrence and availability when querying the platform. Without an offset, recent events that haven't appeared yet could be missed.
- Source Connector: The Source (Connector) for the pipeline, only one may be picked per Pipeline.
- Pipeline Destination: A previously configured Destination. See the Destinations section for more information on how to configure these. Only one Destination may be configured per Pipeline at this time.
-
When you select a Source Connector, the Event Logs section will appear showing which OCSF Event Classes are supported for the Pipeline which are toggleable for inclusion, as shown below. NOTE that each Event Class will go to its own partition/path for object storage so you do not need to create a Pipeline per Event Class. However, that means that a Cribl Stream or Splunk HEC source would get multiple events (if available) which can cause issues with schema collision. To ensure that you only have the right data going to the right place for streaming Destinations, create a Pipeline per Event Class with different Destinations.
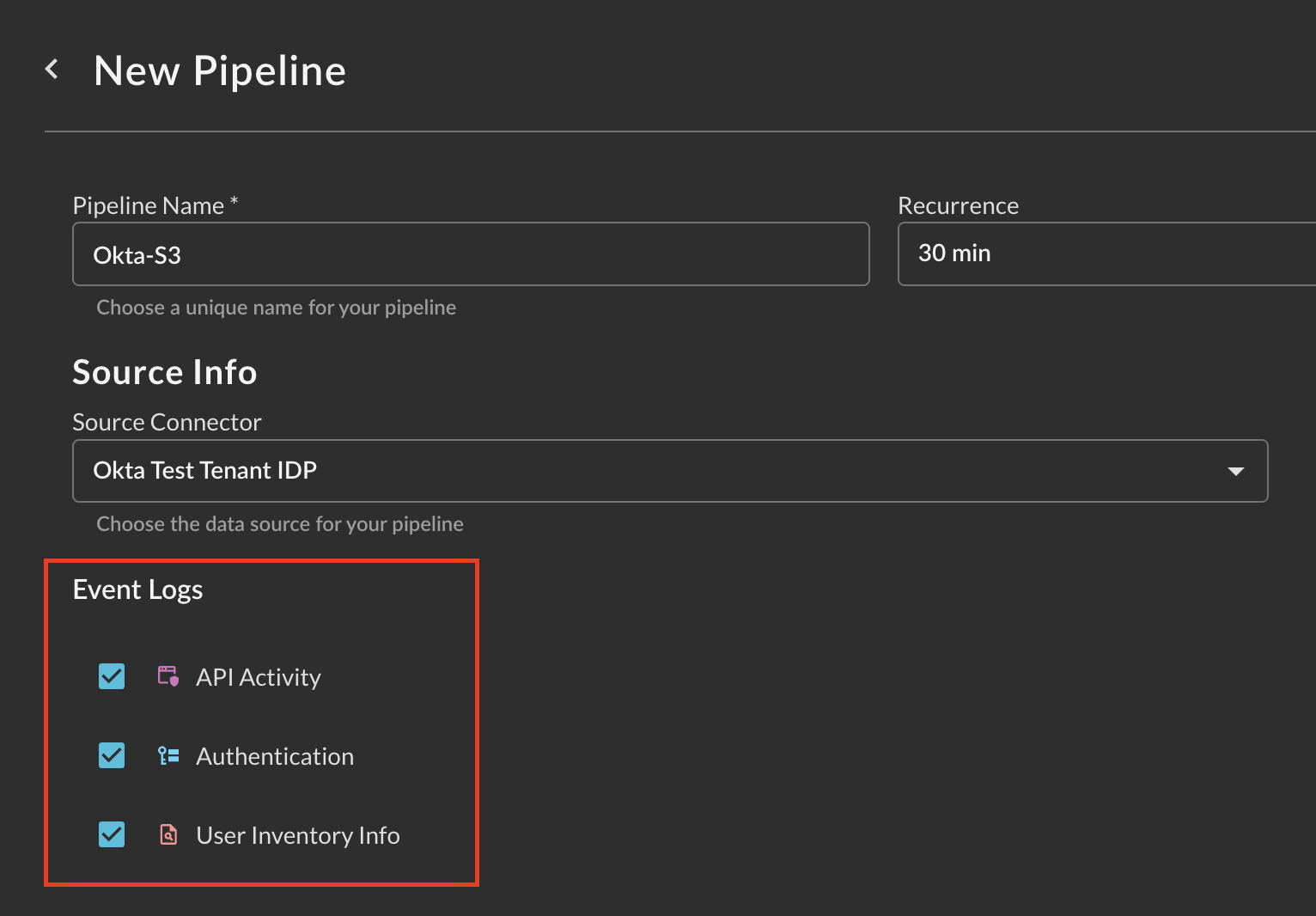
-
Once you have chosen which Event Classes you want to be sent to your Destination, select Submit at the bottom right of the wizard to create the Pipeline.
-
Once your Pipeline is created, you can delete or edit it from the Pipeline Card, and get at-a-glance info such as the Events, Destination, and Source as shown below.
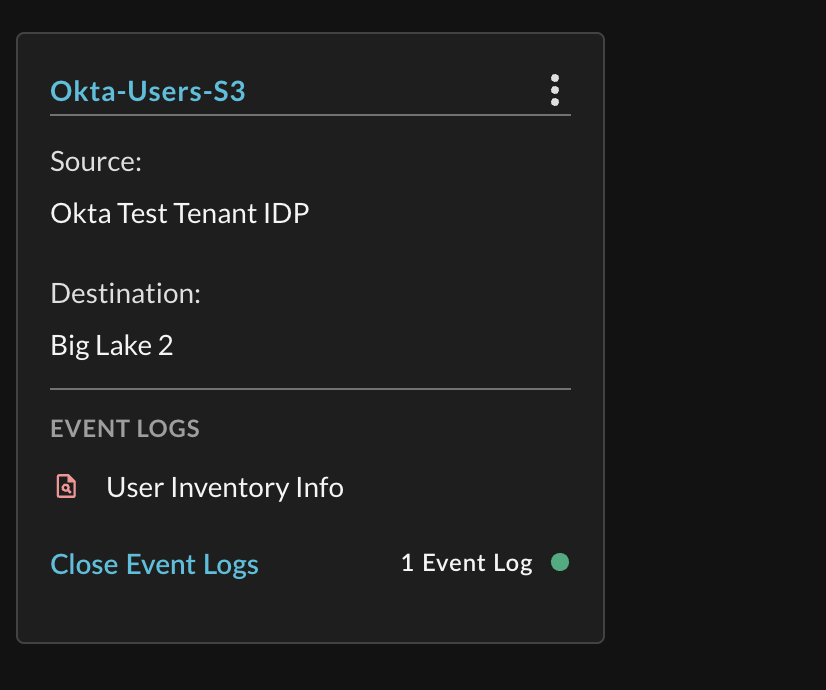
Note, in a future release we will provide Metrics per Pipeline (Records Written, Pass/Fail, Bytes Transferred, Time Elapsed) onto the Cards.
Updated 10 months ago