Databricks
Integrate Query with the Databricks data intelligence / data lake house platform.
TL;DRTo integrate Databricks with Query:
- Create a SQL Workspace and a Personal Access Token for a User with access to the Workspace.
- Add a platform connection in Query using your Personal Access Token, Workspace Server Hostname, Workspace HTTP Path, and relevant Catalog, Schema, and Table/View (or variations of those).
- Use the Configure Schema workflow to introspect and map your data into the Query Data Model.
- Use Query Federated Search to surface any number of indicators, assets, findings, alerts, and anything else stored in your Databricks workspaces by entities, events, and objects.
Overview
Databricks is a multi-cloud Data Lakehouse platform that supports business intelligence (BI), data streaming, warehousing, data science, and security-relevant use-cases. In their own words, Databricks describes the platform as: "the Databricks Data Intelligence Platform is built on lakehouse architecture, which combines the best elements of data lakes and data warehouses to help you reduce costs and deliver on your data and AI initiatives faster. Built on open source and open standards, a lakehouse simplifies your data estate by eliminating the silos that historically complicate data and AI."
Security and IT teams use Databricks as a direct Security Information & Event Management (SIEM) replacement or as an alternative data store to expand SIEM use cases such as enrichment, big data analytics, machine learning (ML), artificial intelligence (AI), and detections. Like other similar warehouses such as Snowflake or Google BigQuery, Databricks has a centralized catalog (the Unity Catalog) that registers all metadata within the platform and organizes like datasets into Schemas which in turn have their own Tables (or Views, Federated Views, and/or Materialized Views) that contain batch- and streaming-data from upstream sources such as Configuration Management Databases (CMDBs), Endpoint, Network, Identity, and Cloud-native data sources.
Databricks' Unity Catalog provides more than just metadata management by also allowing governance, monitoring, observability, and Role-based Access Control (RBAC) into data objects in the catalog. It uses the Delta Lake open table format and uses the Delta Sharing Protocol to support external federation use cases, multi-cloud data hosting, and integration into big data frameworks such as Apache Spark and BI tools such as PowerBI and Tableau.
Query extends the use cases of Databricks -- be it as a direct SIEM replacement or augmentation datastore -- by supporting incident response, investigations, threat hunting, red team targeting operations, and additional continuous compliance, audit, or governance tasks through the usage of federated search. Query does not retain or duplicate any data, does not rely on per-search or ingestion cost models, or require uses to learn how to use the Unity Catalog, Delta Lake table format, write optimized SQL queries, manage additional infrastructure, nor learn Spark or other concepts.
Query interfaces with Databricks using the SQL Warehouse and provides a query planning, translation, and execution engine atop Databrick's SQL warehouse SDK. Query will automatically take advantage of performance tuning done to Delta tables such as clustering, Z-Ordering, and partitioning by using built-in time-based Clustering as well as Delta Lake generated columns. Query uses a simple search interface based on the Query Data Model, a derivate of the Open Cyber Security Format (OCSF) data model, to search for specific attributes in the data stores such as IP Addresses, normalized Events, or specific Objects (such as authorization factors, ASNs, HTTP headers, and more). All SQL queries are parameterized, utilizing predicates and quantifiers, with top-level LIMIT clauses to avoid oversized costs or availability degradation.
Finally, all of this is assured using the no-code Configure Schema workflow which allows tables of any complexity to be modeled into the QDM so users do not need to pre-transform data or invest in a medallion data layout model to use with Query.
Prerequisites
The Query integration with Databricks requires a SQL Warehouse as well as Personal Access Tokens (PATs) being created. Ensure the user associated with the PAT does not have any RBAC restrictions within the Unity Catalog for whichever combination of catalogs/schemas/tables/views you wish to view.
Known LimitationsQuery's Connector with Databricks has the following known limitations.
- Federated Tables or Federated Views that have downstream dependencies such as partition usage enforcement (e.g., GCP BigQuery tables) will not work.
- Query does not determine in a Warehouse is in a running state, it may lead to Query errors or connection test failures.
- Custom Z-Ordering, Clustering, and/or Partitioning that does not use time-based fields will not be used.
- Normalized mapping from data types that become Python
listsare not supported, this data will be provided in the_raworunmappedfields within a Query result.
Retrieve SQL Warehouse data
Query requires a SQL Warehouse to integrate with your data. For more information see the Create a SQL warehouse section of the Databricks documentation. To retrieve the required connection parameters for the Databricks Connector (Server Hostname and HTTP Path), refer to the following steps.
-
From the homepage of your Databricks workspace, navigate to SQL Warehouses and select the warehouse you wish to connect to, such as the Starter Warehouse as shown below (FIG. 1).
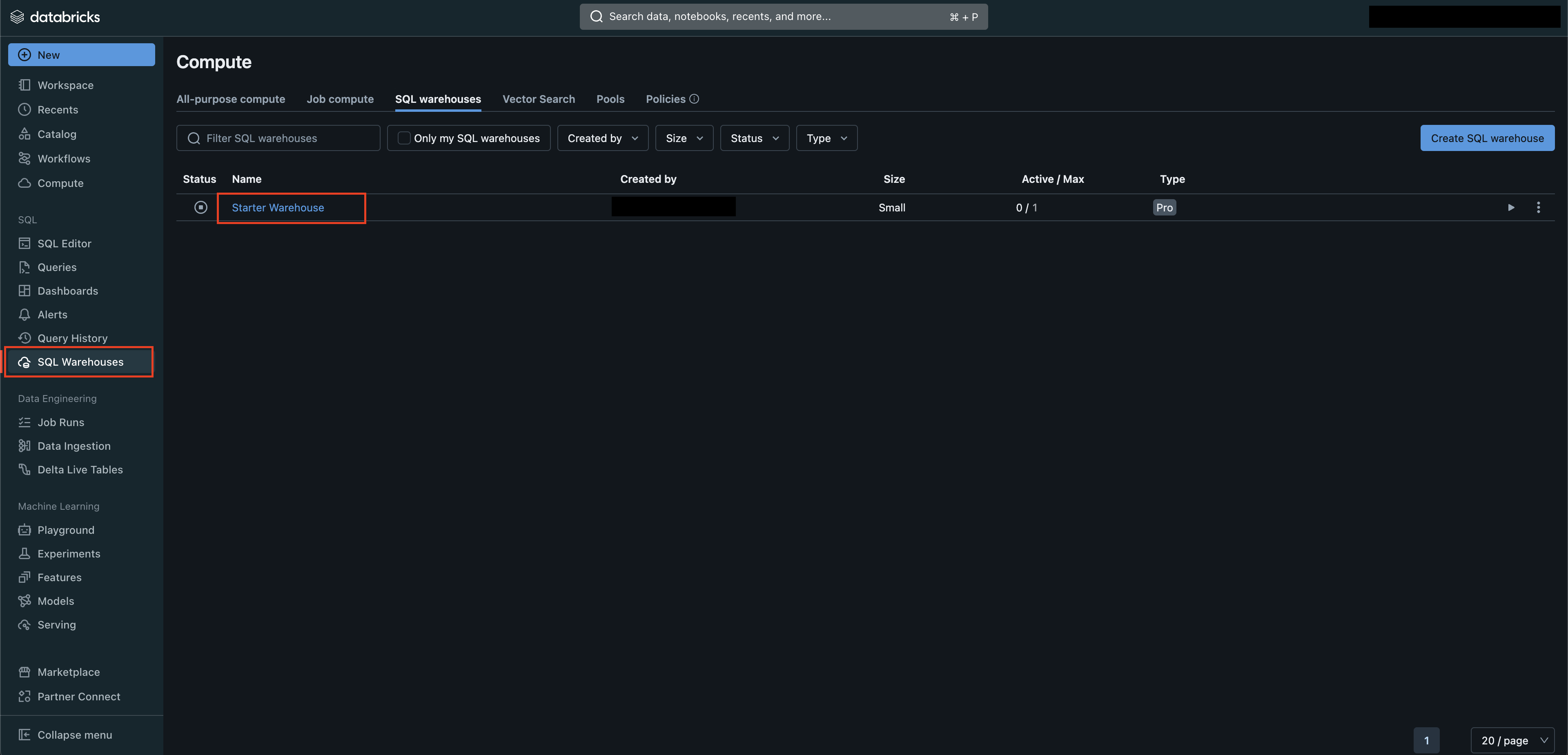
FIG. 1 - Navigating to the SQL Warehouse menu in Databricks
-
Select the Connection details tab and copy the values for Server hostname and HTTP path as shown below (FIG. 2). Query defaults to using HTTPS connectivity by default for your Warehouse.
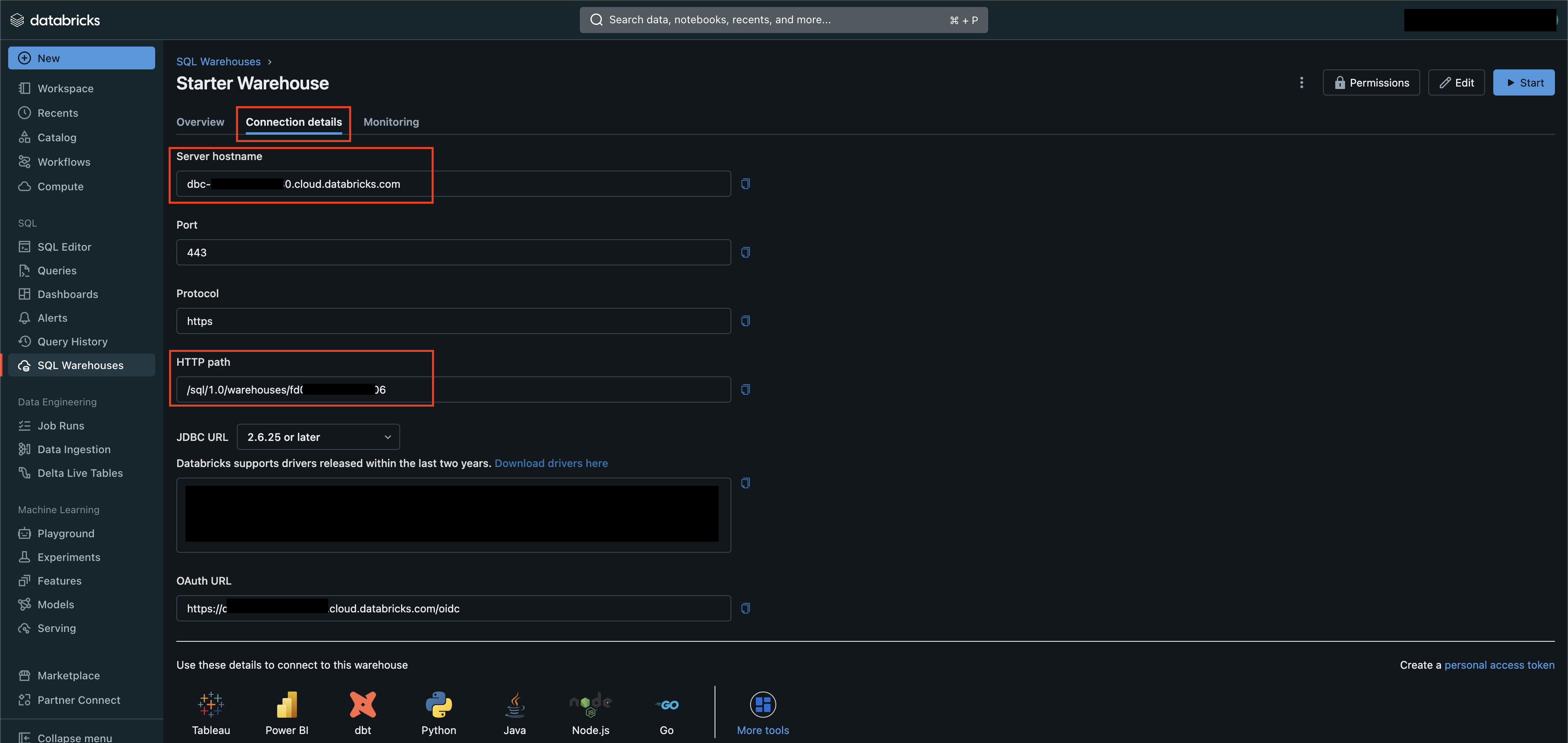
FIG. 2 - Retrieve Server hostname and HTTP path parameters
If desired, consider modifying the Auto stop value within the Overview tab if your Security Operations Center (SOC) or Managed Security Service Provider (MSSP) who will use Query requires 24x7x365 access to your Databricks hosted data.
Generate Private Access Token (PAT)
To create a PAT, select Create a personal access token from the Connections detail tab of your SQL Warehouse. Otherwise, use the following steps. See the Databricks personal access token authentication section of the Databricks documentation for more information.
-
From your Databricks workspace, select your User at the top-right of the screen and select Settings from the dropdown menu, as shown below (FIG. 3).
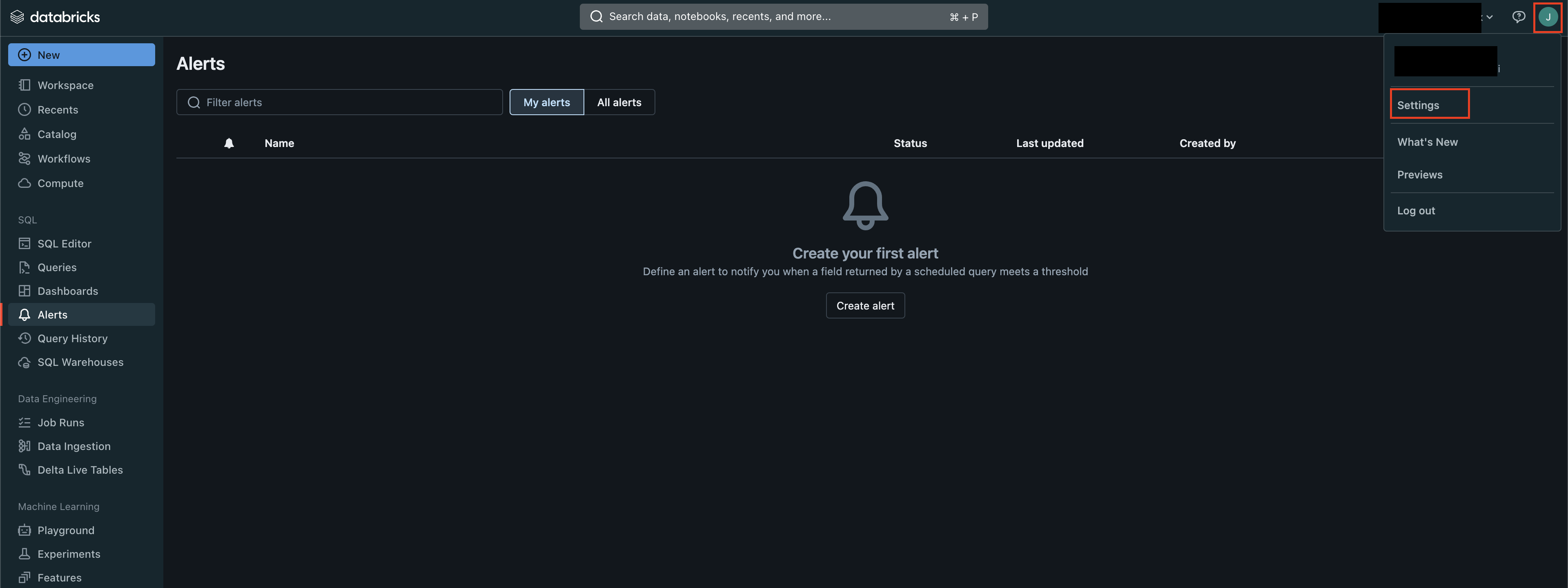
FIG. 3 - Databricks User settings menu
-
Under the User submenu in the left-hand navigation pane, select Developer and then select the Manage option from the Access tokens section as shown below (FIG. 4).
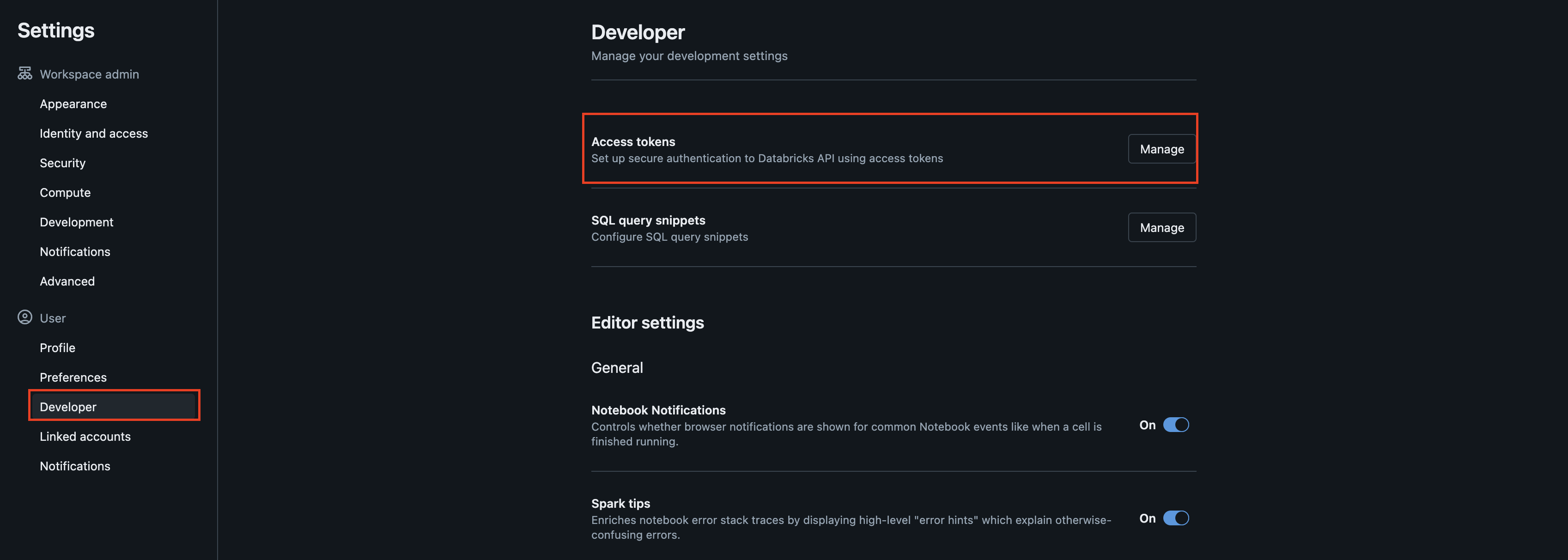
FIG. 4 - Access tokens management Developer options
-
Select Generate new token, add a Comment and specify a Lifetime value to set an automatic expiration for a given number of days and select Generate, as shown below (FIG. 5). If you do not provide a Lifetime value, the PAT will last indefinitely.
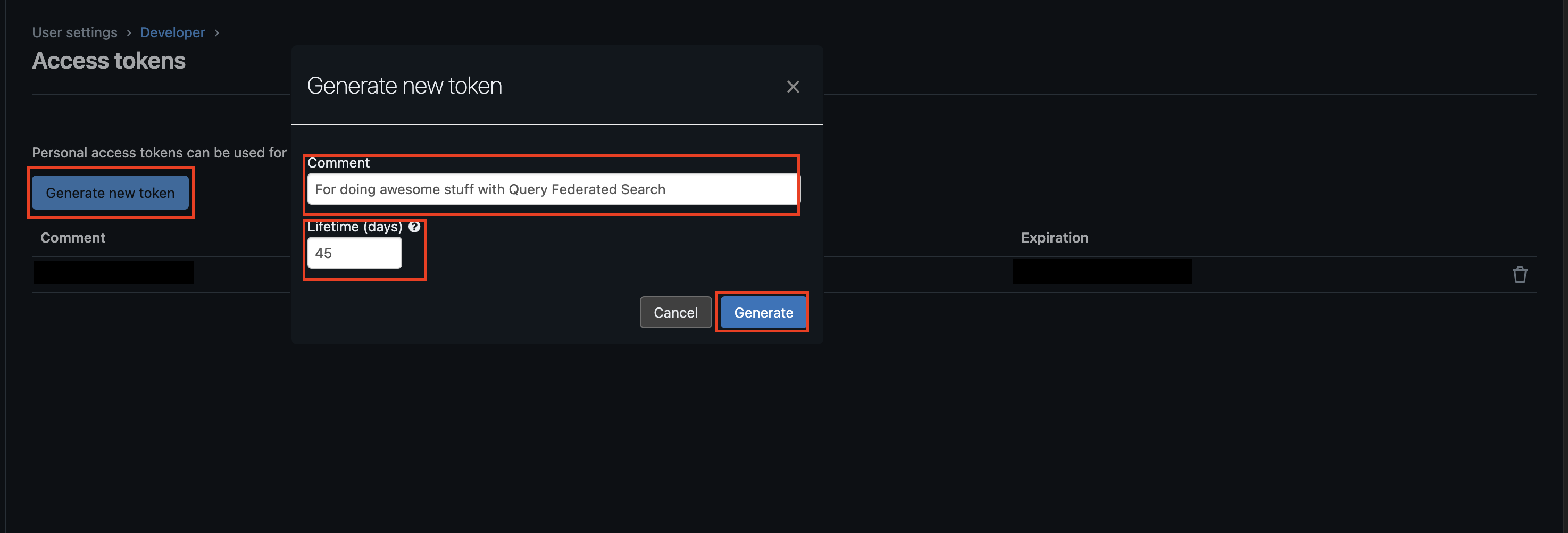
FIG. 5 - Generating a new Databricks Personal Access Token (PAT)
-
Ensure you copy and store the PAT in a secure location before selecting Done in the token preview screen, as shown below (FIG. 6).
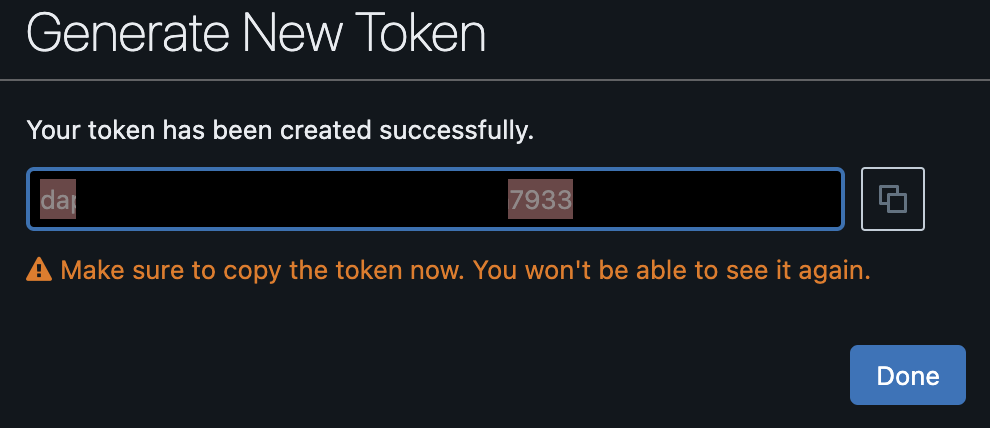
FIG. 6 - Copy Databricks PAT
If you do not copy the PAT, delete it and create another one. Query stores PATs as Secrets within an AWS Secrets Manager secret dedicated to a specific customer tenant and uses a specifically crafted AWS Key Management Service (KMS) Custom Managed Key (CMK) for the secret as well. Only specific Databricks query execution infrastructure is permitted decryption and secret usage IAM permissions which is dedicated per Connector you create. This allows you the option to use one or many PATs for different Connectors.
Connector Security ConsiderationsDue to the way that metadata is secured in Query's backend, you cannot Read or Write to a Dynamic Schema Connector (such as Databricks) after it is created. If you set aggressive expiration dates on your PAT, you will be required to create a new Connector and redo your mapping per Connector as well.
Configure a Databricks Connector
The Databricks Connector is a dynamic schema platform configuration. Static schemas are platforms in which the Query team pre-configures the type of data normalization that happens and a dynamic schema platform gives the user control for mapping and normalizing data into the Query Data Model. For dynamic schemas, Query provides a no-code data mapping workflow to allow you to map your source data into the Query Data Model. For more information, see the Configure Schema and the Normalization and the Query Data Model sections, respectively.
To connect to your Databricks tables, Query requires your server hostname, HTTP path of your SQL Warehouse, the Personal Access Token (PAT), as well as Catalog, Schema (Database), and Table name(s).
Query stores the PAT in AWS Secrets Manager encrypted with an AWS Key Management Service (KMS) Customer Managed Key dedicated to your Query tenant. Every action within Query's backend requires with a policy-as-code agent - Open Policy Agent - and the only principal able to access the Secret and its KMS CMK is a dedicated AWS IAM Role that powers the infrastructure used for the Databricks Connector dedicated to your tenant.
Configure Schema LimitationsDue to limitations in the introspection and mapping process, you may only map one Databricks table per Connector. There are not any limits to the amount of Connectors you can create.
-
Navigate to the Connections page, select Add Connections, and select Databricks from the
Data Lakes and Data Warehousescategory, optionally type Databricks in the search bar as shown below (FIG. 7).
FIG. 7 - Locating the Databricks Connector
-
In the Connection Info section of the platform connector, provide the following details, select Save, and then Test Connection as shown below (FIG. 8).
-
Connection Alias Name: A contextual name for the Connector, this is used to disambiguate multiple of the same connector.
-
Platform Login Method: Leave the default value
Default Login. -
Server Hostname: The Server Hostname of the SQL warehouse you want to use for querying tables.
-
HTTP Path: The HTTP Path of the SQL warehouse you want to use for querying tables.
-
Personal Access Token: A Personal Access Token generated that provides secure authentication to Databricks. Ensure that this value is not expired. YOU CANNOT EDIT OR RETRIEVE THIS VALUE AFTER CREATION -- IF YOU SET PAT EXPIRATIONS YOU MUST RECREATE THE CONNECTOR.
-
Catalog Name: The name of the catalog that contains the specific schema and table you want to query.
-
Schema Name: The schema (database) name in the provided catalog that contains the table you want to query.
-
Table Name: The table name that contains the data you want to query. Can also be a View, Federated Table, Federated View, or Materialized View.
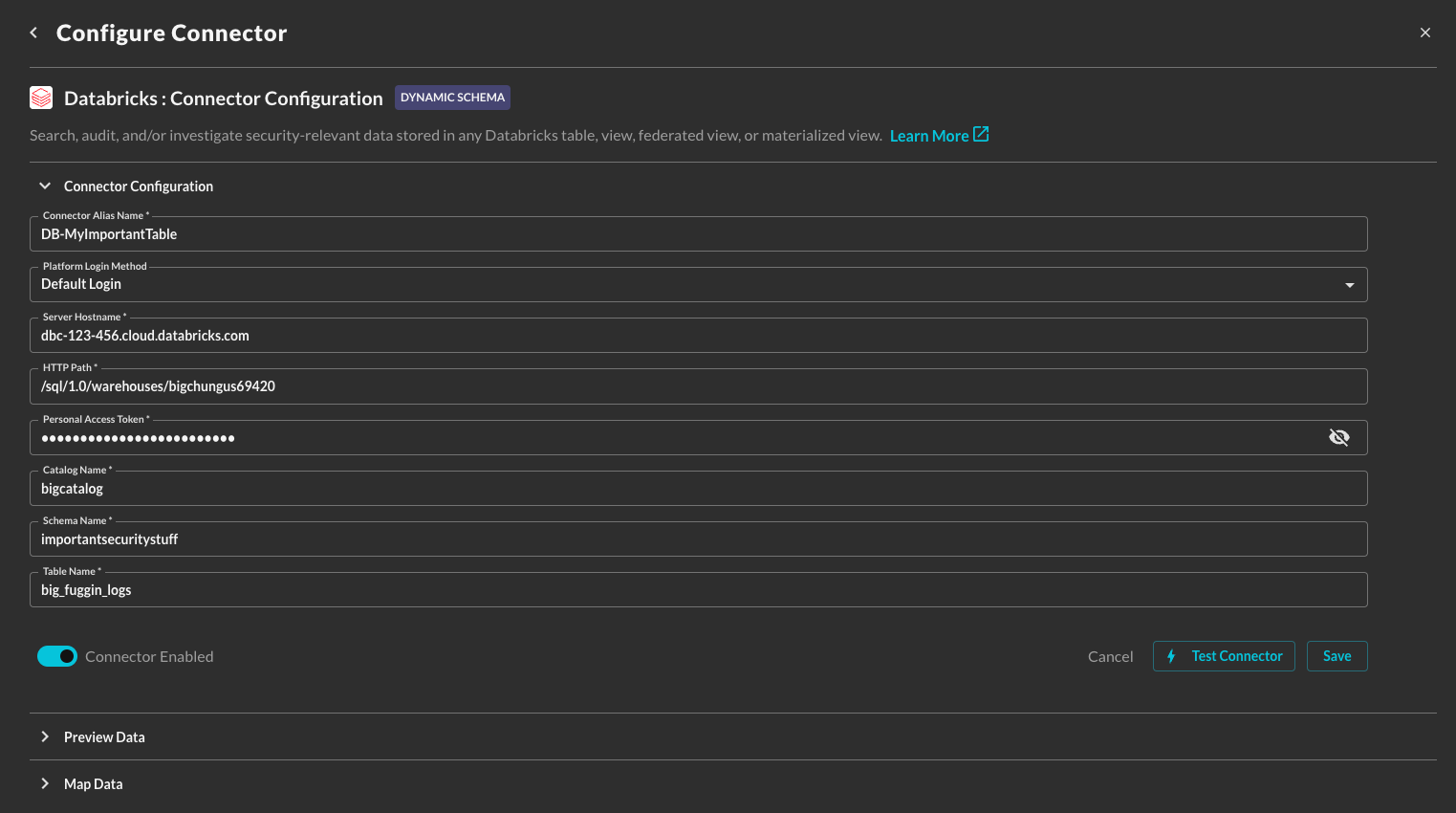
FIG. 8 - Providing Connection Info for Databricks in the Configure Connector screen
-
-
Execute the Configure Schema workflow to map your target table data into the QDM.
After completing the Configure Schema workflow, you are ready to perform Federated Searches against your Databricks tables (or various flavors of views).
Querying the Databricks Connector
Querying your data completely depends on how your configured your schema mapping, as not all data sources are created the same, you can theoretically query across any number and combination of the currently supported Entities within the Query Federated Search platform.
- Hostnames (and Domains)
- IP Addresses (IPv4 and IPv6)
- MAC Addresses
- User Names
- Email Addresses
- URL Strings (and URIs)
- File Names
- Hashes (e.g., MD5, SHA1, SHA256, SSDEEP, VHASH, etc.)
- Process Names
- Resource IDs
- Ports
- Subnets (e.g.,
192.168.1.0/24or2001:0db8:85a3:0000::/64) - Command Lines (e.g.,
python3 encrypted.pyorssh user@ubuntu-ip-10-0-0-1) - Country Code (e.g.,
USorCN) - Process ID
- User Agent
- Common Weaknesses & Enumerations (CWE) IDs (e.g.,
CVE-2024-100251) - Common Vulnerabilities & Enumerations (CVE) IDs (e.g.,
CWE-79) - User Credential UID (e.g., AWS User Access Key ID -
AKIA0007EXAMPLE0002) - User ID
- Group Name
- Group ID
- Account Name
- Account ID
- Script Content
Resources
Refer to the previous sections' hyperlinks for more information on specific resources, services, tools and concepts. For further help with creating tables and performance tuning, consider some of the resources below.
- Create a SQL Warehouse: https://docs.databricks.com/en/compute/sql-warehouse/create.html
- Databricks personal access token authentication: https://docs.databricks.com/en/dev-tools/auth/pat.html
Troubleshooting
- If you recently changed your permissions / Role in Query, log out and in again and clear your cache if you cannot Save or Test Connection.
- Verify your Databricks user has proper Role access to the Catalog/Schema/Table/View
- Verify your PAT is not expired or rolled over
- Verify you are using the correct connection parameters such as your hostname, SQL DB ID, PAT, and otherwise.
- Verify the name and location of your Catalog, Schema, and/or Tables.
If you have exhausted the above Troubleshooting list, please contact your designated Query Sales Engineer or Customer Success Manager. If you are using a free tenant please contact Query Customer Success via the Support email in the Help section or via Intercom within your tenant.
Updated 8 months ago