Product Architecture
System Design
Query is a modern, cloud-native web application that searches across your disparate security data sources without the cost of moving that data to a centralized store. We use the best capabilities of Amazon Web Services to provide scalability, security, and efficiency.
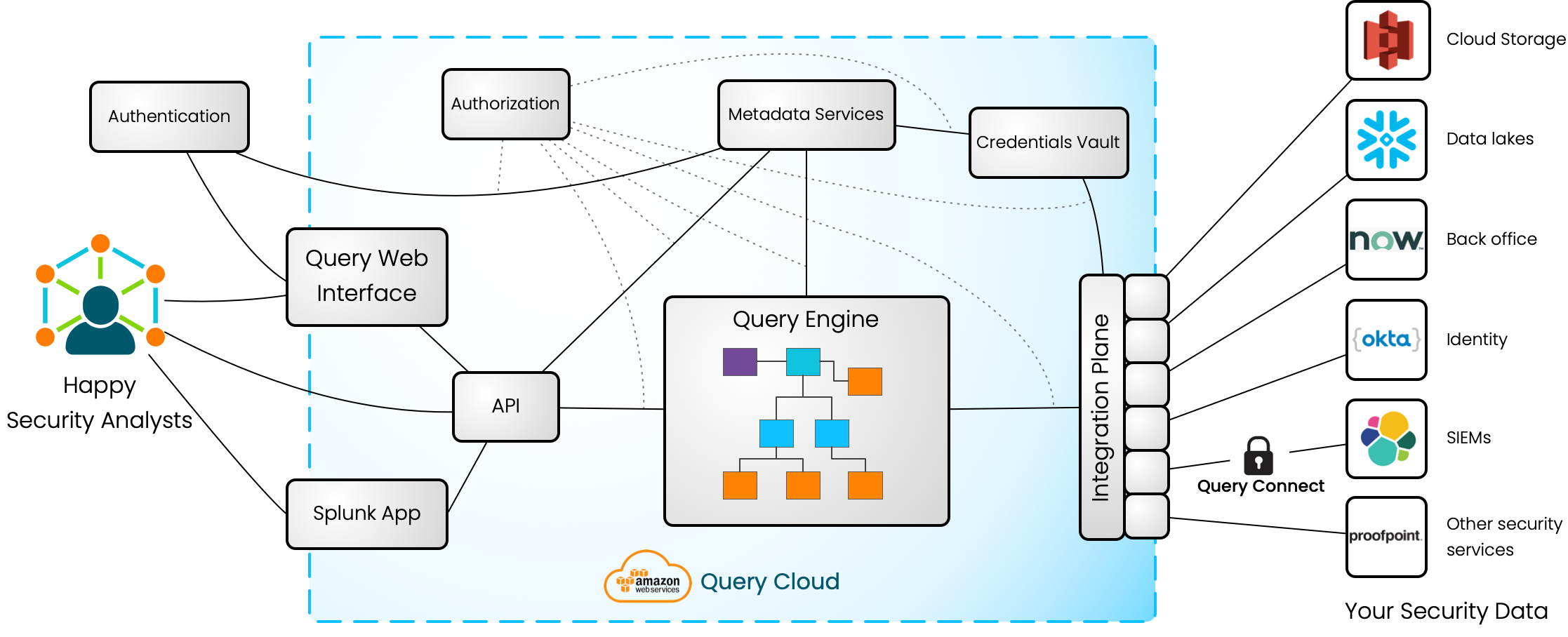
Query's System Design
Query's Key Components:
- Interfaces: Our GraphQL API allows many ways to use Query: through our web interface, an app in your SIEM, or headless by building directly against our API.
- Authentication: We use Auth0 by Okta to authenticate your users against your identity provider of choice. Once your identity provider has been configured, you can use Query without any IAM worries.
- Authorization: Every request to and within the Query platform is authorized according to the identity we receive from your identity provider.
- Query Engine: Our Query Engine plans which data sources to query and how to combine and filter the results.
- Integration Control Plane: Our integrations connect us to the many disparate sources that house your security data. Each integration translates your search terms into an efficient query, then normalizes the responses it receives.
Data Model
A central tenet of Query is that security data is best represented as a graph. By normalizing data to a common model, Query is able to translate simple requests into sophisticated search operations with filters, joins, and contextual enrichment across many sources.
Our data model is based on OCSF, an open-source schema for cybersecurity data led by AWS, Splunk, and others. OCSF is a graph-centric schema that relates objects and events across your environment. To learn more about how we use OCSF, see Normalization and the OCSF Data Model.
No one data source – not even your SIEM – has all of the data to complete your security graph. With Query, your graph is built from many varying data sources without you having to think about it. What would have been a tedious and complicated investigation – or an expensive data warehousing project – is fast and easy with Query thanks to our data model.
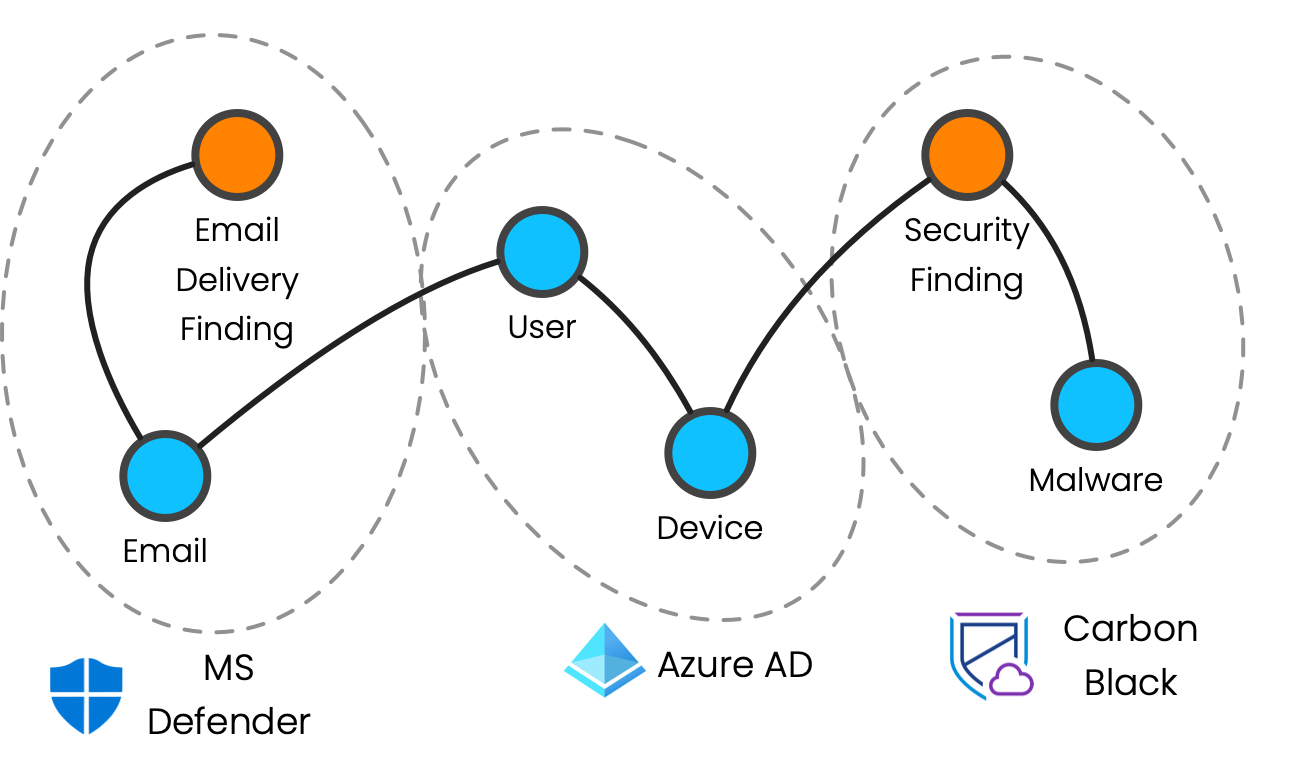
An example of how your security graph lives across many data sources.
How Queries Work
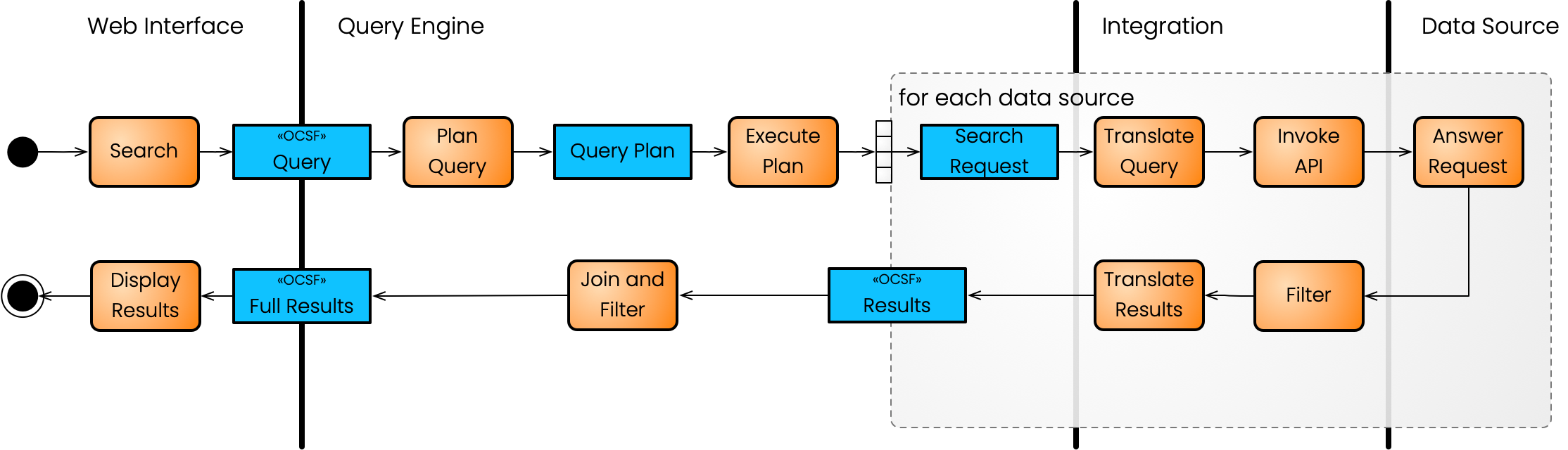
All search operations and results are described in Query's data model.
When a search is made, the Query Engine decides how much, if any, of the search each data source can answer. The Query Engine also decides how to join and filter the results after each data source has responded. This query plan is executed by sending the relevant search operations to each integration.
These partial searches are performed in parallel as much as possible. If your search requires an answer from one data source before making a request of another source, the later steps of the query plan will be withheld until the earlier steps have completed. For example, needing to retrieve devices for a user by email address from a corporate directory, then finding malware detections for that device from an EDR platform.
Each integration is responsible for translating the search request it receives into an efficient query against its target data source, – its piece of the larger query plan. Some searches may require multiple API requests of a source in order to retrieve the requested results.
Most data sources only support a small subset of the search operations you can perform in Query. For instance, a data source may only support searching by a limited number of fields or may not support combining filters with a Boolean OR.
When practical, Query overcomes these shortcomings by reordering requests, by fetching more data than required, and filtering before completing a search, or by other means. Because this may lead to very large and long-running queries, it is not always desirable. Review the documentation for your specific integrations to better understand how each behaves.
Once a data source has returned results, those results are transformed back into Query's data model before the Query Engine combines them with the responses from the other sources queried by your search. Most data sources have fixed, static schemas that Query normalizes for you. But some data sources, like SIEMs and cloud blob stores, have dynamic schemas. Query will need your help in mapping data from these platforms to our data model.
Once data has been normalized, additional data sources may need to be queried and this process repeated until all steps in the query plan have completed. The combined result set is then returned to the end user. You don't have to open new browser tabs or create pivot tables in Excel – Query does the work of combining your data for you.
When possible, partial results are returned so that users do not have to wait for every data source to answer their search. But in some cases, such as when the search calls for a result set to be intersected with another result set, results must be withheld until some or all data sources have answered the query.
Updated about 1 year ago
What’s Next
See how we've built security into Query from the bottom up and how we treat your information with care