Cribl Stream - HTTP Destination
Write data the right way into Cribl Stream HTTP Sources, powered by Query Security Data Pipelines.
Overview
Cribl Stream is a powerful data engine that gives you the freedom to choose your data's destination, format, and fidelity. It allows you to collect, reduce, enrich, and route machine data to any analytics tool or data lake.
HTTP Destinations in Cribl Stream enable you to send processed and transformed data to any HTTP endpoint. This provides immense flexibility, allowing integration with a wide array of services and platforms that accept data via HTTP. When using HTTP Streams with Cribl, customers typically either create Packs or Pipelines to process events from a single Stream, or they dedicate a Stream per event source and event class, or even a Stream per event class across multiple connectors for more granular control and routing.
Data is sent over the wire in batches of 1000 records, compressed using GZIP, and formatted as JSON.
Prerequisites
To configure an HTTP Destination in Cribl Stream, you'll first need to set up an HTTP/S Source in your Cribl Stream instance to receive the data. Follow these steps:
- Access your Cribl Stream Instance: Ensure you have access to a running Cribl Stream instance.
- Configure an HTTP/S Source:
- Navigate to Sources and add a new HTTP/S (Bulk API) Source.
- In General Settings, provide an Input ID, and note the Address and Port where Cribl Stream will listen for incoming data. This combination will form part of your ingest URL (e.g.,
http://<Address>:<Port>/). - In Authentication, configure Auth tokens to secure your source.
- Under Optional Settings, note the Base path for Cribl HTTP event API. This path, when appended to your address and port, will complete your ingest URL (e.g.,
http://<Address>:<Port>/<Base path for Cribl HTTP event API>). You can use the default path provided or customize it.
- Network Connectivity: Ensure there is network connectivity between your data sender and the configured Cribl Stream instance.
- Required Permissions: Verify you have the necessary permissions or roles to configure Sources and Destinations within Cribl Stream.
Configure a Cribl Stream - HTTP Destination
If you already have an existing Destination, skip to Step 4.
-
Navigate to the Pipelines feature in the Query Console and select + New Pipeline form the top of the page, as shown below (FIG. 1).
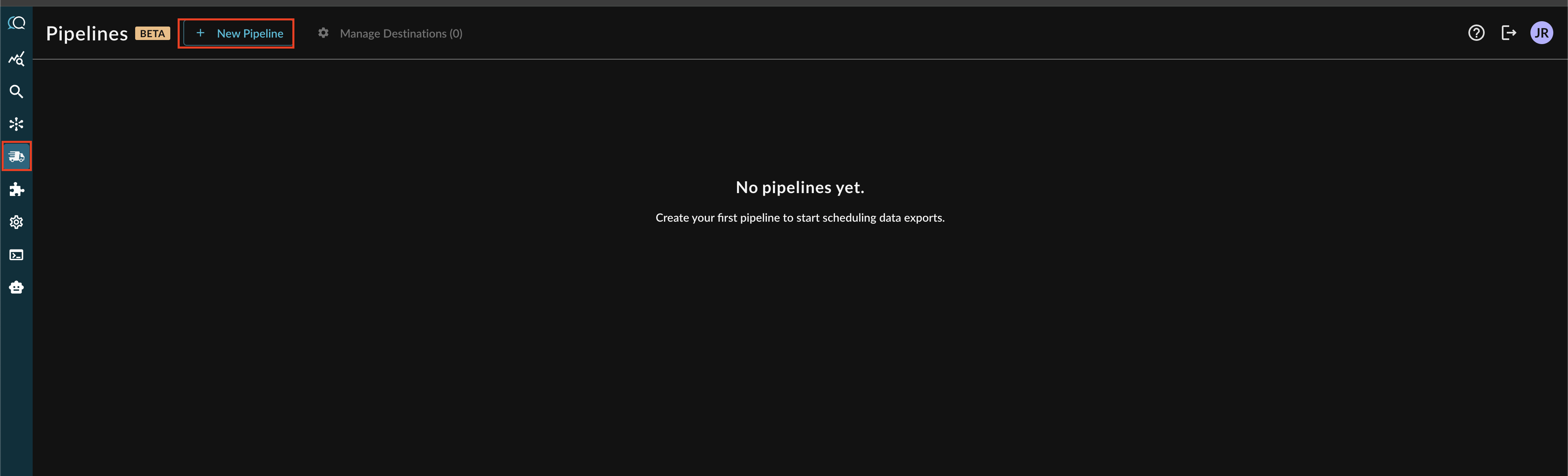
FIG. 1 - Adding a new Pipeline
Note: If you already have an existing Destination, this toggle will read Manage Destinations (n) instead, as shown below. You can directly add a new Destination from the Destination Manager, as shown below (FIG. 2).

FIG. 2 - Manage Destinations highlighted for existing Destinations
-
Before configuring your pipeline, if a destination does not exist, select Create New Destination within the Pipeline creation interface as shown below (FIG 3).
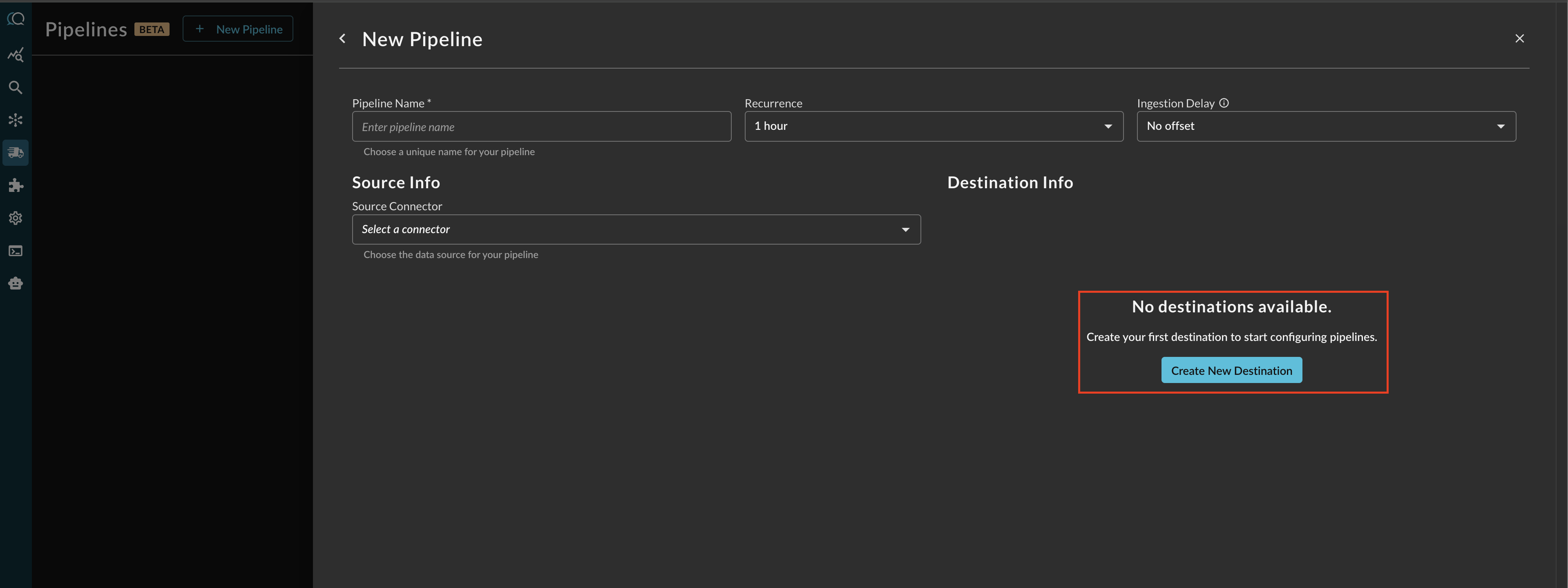
FIG. 3 - Creating a new Destination from the Pipeline configuration screen
-
Provide a Destination Name, you can reuse these destinations across multiple pipelines. From Platform select
Cribl, and provide the following parameters as shown below (FIG. 4). Once completed, select Create.-
Hostname: The hostname of your Cribl instance, the pattern will be similar to
default.main.<instance_name>.cribl.cloud. -
Port: The Port setup in your Cribl Stream HTTP (Bulk API) source, typically this defaults to
10000or10800. -
Endpoint: The bulk API endpoint setup in the Source, the default value is
/cribl/_bulk. -
Token: The Auth Token setup in your Cribl Stream HTTP (Bulk API) source, this is required.
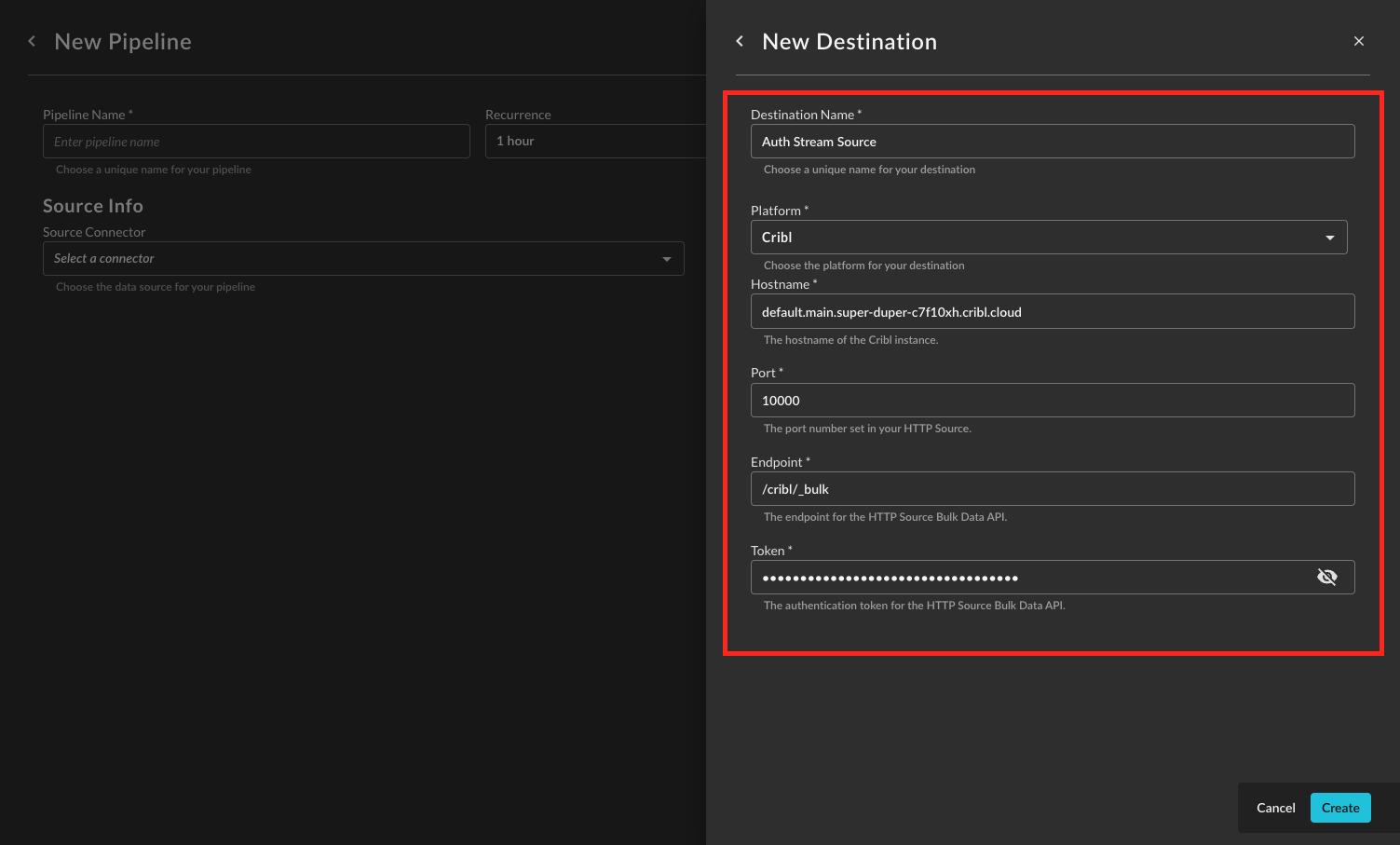
FIG. 4 - Configuring a Cribl Stream HTTP (Bulk) API Destination
-
Operationalizing Cribl Stream - HTTP Destinations
This section outlines how to operationalize data flowing through Cribl Stream, specifically focusing on data ingested via an HTTP/S (Bulk API) Source and subsequently directed to Cribl Lake for search and analysis.
1. Ingest Data via HTTP/S (Bulk API) Source
As detailed in the Prerequisites section above, configure an HTTP/S (Bulk API) Source in your Cribl Stream instance to receive incoming data. This serves as your initial ingestion point.
2. Route Data to Cribl Lake Destination
After ingesting data through your HTTP/S Source and optionally processing it with Pipelines or Packs, you can configure a Cribl Lake Destination to send this data to Cribl Lake. This destination automatically optimizes partitioning for Cribl Search.
To configure a Cribl Lake Destination:
- Ensure you are using Cribl Stream version 4.8 or later in Cribl.Cloud or a customer-managed hybrid Stream Worker Group.
- For full Cribl Lakehouse functionality, it is recommended to parse events into distinct fields using the Stream Parser Function before sending data to Cribl Lake.
- In Cribl Stream, navigate to Destinations and add a new Cribl Lake Destination.
- Provide an Output ID and select the desired Cribl Lake Dataset where your data will be stored.
3. Search Data with Cribl Search
Once your data is in Cribl Lake, you can use Cribl Search to query and analyze it. Cribl Search is preconfigured with a Dataset Provider called cribl_lake, allowing immediate searching of your Cribl Lake Datasets.
To search your data:
- Access Cribl Search by navigating to "Products" and then selecting "Search" from your Cribl Organization's top bar.
- Utilize the search bar to query your Cribl Lake Datasets. For example, a basic query might look like:
search <your_dataset_name> | where field_name = 'value'. - Cribl Search can leverage a Lakehouse for significantly faster searches, provided the search's time range is within the Lakehouse's retention period. A tracking bar will indicate if a search successfully used a Lakehouse.
4. Conduct Federated Search with Query Connector for Cribl Search
For advanced querying capabilities, especially over multiple Lake Datasets, leverage the Query Connector for Cribl Search. This connector enables Federated Search, allowing you to combine and search data across disparate sources, including multiple Cribl Lake Datasets.
To use the Query Connector for Federated Search:
- Ensure the Query Connector for Cribl Search is configured within your Query.AI environment.
- You can then formulate queries that span across different Cribl Lake Datasets, enabling a unified view and analysis of your data landscape.
This setup provides a comprehensive flow from data ingestion via HTTP, through processing in Cribl Stream, to storage in Cribl Lake, and finally, powerful searching with Cribl Search and Federated Search capabilities via the Query Connector.
Updated 10 months ago