Google Cloud Storage (GCS) Destination
Write data the right way into Google Cloud Storage buckets, powered by Query Security Data Pipelines.
Overview
Google Cloud Storage is Google Cloud's object storage service, which is used for simple archival storage as well as a storage engine to back security data lakes and security data lakehouses onto in combination with query engines such as Google BigQuery or used as an intermediary storage between ClickHouse, Databricks, and/or Snowflake. BigQuery is natively integrated with Google Cloud Storage and can be ingested into native tables or setup as an external table using BigLake to use as a more traditional lakehouse.
The Google Cloud Storage Destination for Query Security Data Pipelines writes data the right way pertaining to the aforementioned usage. The data is written in the following ways to aid in schema registration and performant reads:
- All data is written into OCSF-formatted Apache Parquet, partitioned on the
timefield by year, month, day, and hour. The file names are seeded by a 16 digit UUID and the datetime to avoid object overwrites. - Data is compressed with Snappy compression that offers the best decompression speed for querying the data.
- Data is written into Hive-like partitions (e.g.,
source=your_connector_name/event=detection_finding/year=2025/month=08/day=21/hour=17/) which is easily discovered by AWS Glue and other metadata catalogs and query engines. The performance of these partitions is only used in certain query engines and for auto ingest into BigQuery.
To support writing the data, Query uses Google Service Accounts with JSON Keys that are provided with appropriate GCP IAM Roles associated with the Service Account. To audit the behavior, use GCP Audit logs and search for your Service Account by ID or email.
Information on thesourcepartitionThe ensure that there will not be any issues with downstream query engines, your Connector Name (the Source) is converted into a lowercase string that only contains underscores.
All special characters except for whitespace, periods (
.), and hyphens (-) are stripped. Whitespace, periods, and hyphens are replaced by underscores (_). Finally, the entire string is lowercased.For example,
My-Data.Source@2024will be converted intomydata_source2024.
Prerequisites
To ensure Query Security Data Pipelines can write data to your Google Cloud Storage (GCS) buckets, you need to set up a Google Cloud Service Account with appropriate permissions. Follow these steps:
1. Create a Google Cloud Service Account
A service account is a special type of Google account intended to represent a non-human user that needs to authenticate to Google Cloud services.
- Open the Google Cloud Console: Navigate to the IAM & Admin > Service Accounts page.
- Select your project: Ensure the correct Google Cloud project is selected.
- Click
+ CREATE SERVICE ACCOUNT:- Service account name: Enter a descriptive name (e.g.,
query-security-data-pipeline). - Service account ID: This will be automatically generated based on the name.
- Service account description: (Optional) Add a brief description of the service account's purpose.
- Service account name: Enter a descriptive name (e.g.,
- Click
DONE.
2. Create and Download a JSON Key for the Service Account
A JSON key is a credential file that allows applications to authenticate as your service account.
- Navigate to the Service Accounts page: In the Google Cloud Console, go to IAM & Admin > Service Accounts.
- Click on the service account you just created.
- Select the
KEYStab. - Click
ADD KEY>Create new key. - Select
JSONas the Key type and clickCREATE. - The JSON key file will be downloaded to your computer. Keep this file secure, as it acts as a password for your service account.
3. Create a Custom IAM Role with storage.objects.create Permission
storage.objects.create PermissionWhile you could use a predefined role like Storage Object Creator, it's a best practice to create a custom role with only the necessary permissions (least privilege).
- Open the Google Cloud Console: Navigate to the IAM & Admin > Roles page.
- Click
+ CREATE ROLE. - Provide Role details:
- Title: Enter a descriptive title (e.g.,
Query Security GCS Object Writer). - ID: This will be automatically generated.
- Description: (Optional) Describe the role's purpose.
- Launch stage: Select an appropriate stage (e.g.,
General Availability).
- Title: Enter a descriptive title (e.g.,
- Click
ADD PERMISSIONS:- In the "Filter table" search bar, type
storage.objects.create. - Select the
storage.objects.createpermission. - Click
ADD.
- In the "Filter table" search bar, type
- Click
CREATE.
4. Grant the Custom IAM Role to the Service Account
Now, you need to assign the custom role to the service account, giving it permission to create objects in your GCS buckets.
- Open the Google Cloud Console: Navigate to the IAM & Admin > IAM page.
- Click
+ GRANT ACCESS. - In the "New principals" field, enter the email address of the service account you created (e.g.,
query-security-data-pipeline@your-project-id.iam.gserviceaccount.com). - In the "Select a role" dropdown, search for and select the custom role you created (e.g.,
Query Security GCS Object Writer). - Click
SAVE.
Your Google Cloud Service Account is now configured with the necessary permissions to allow Query Security Data Pipelines to write data to your GCS buckets.
Configure a Google Cloud Storage Destination
If you already have an existing Destination, skip to Step 4.
-
Navigate to the Pipelines feature in the Query Console and select + New Pipeline form the top of the page, as shown below (FIG. 1).
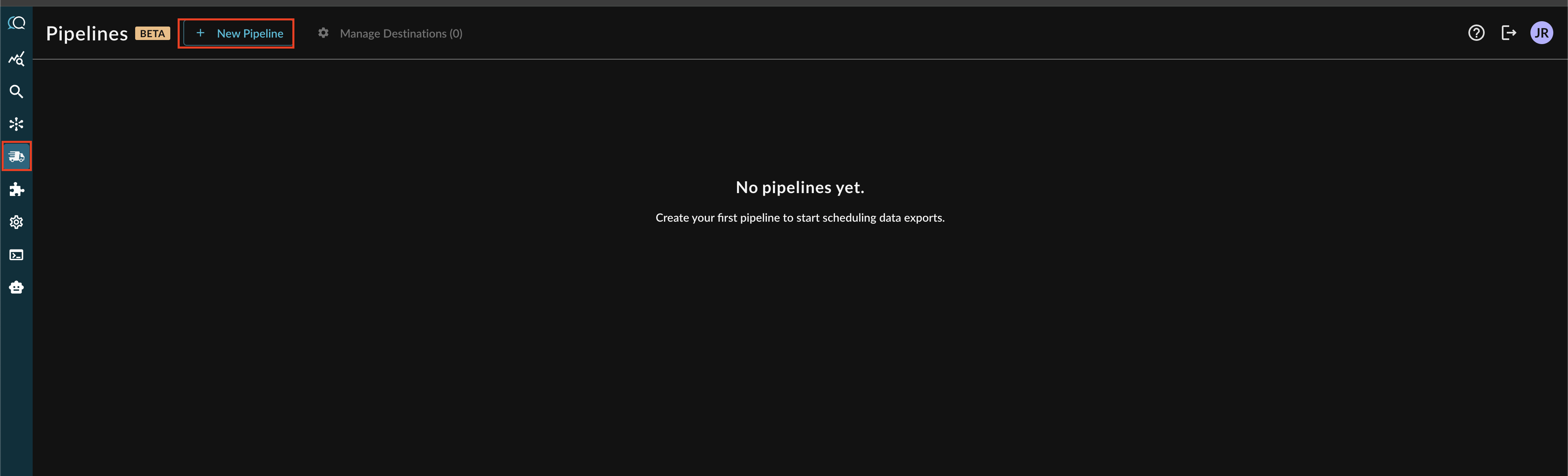
FIG. 1 - Adding a new Pipeline
Note: If you already have an existing Destination, this toggle will read Manage Destinations (n) instead, as shown below. You can directly add a new Destination from the Destination Manager, as shown below (FIG. 2).

FIG. 2 - Manage Destinations highlighted for existing Destinations
-
Before configuring your pipeline, if a destination does not exist, select Create New Destination within the Pipeline creation interface as shown below (FIG 3).
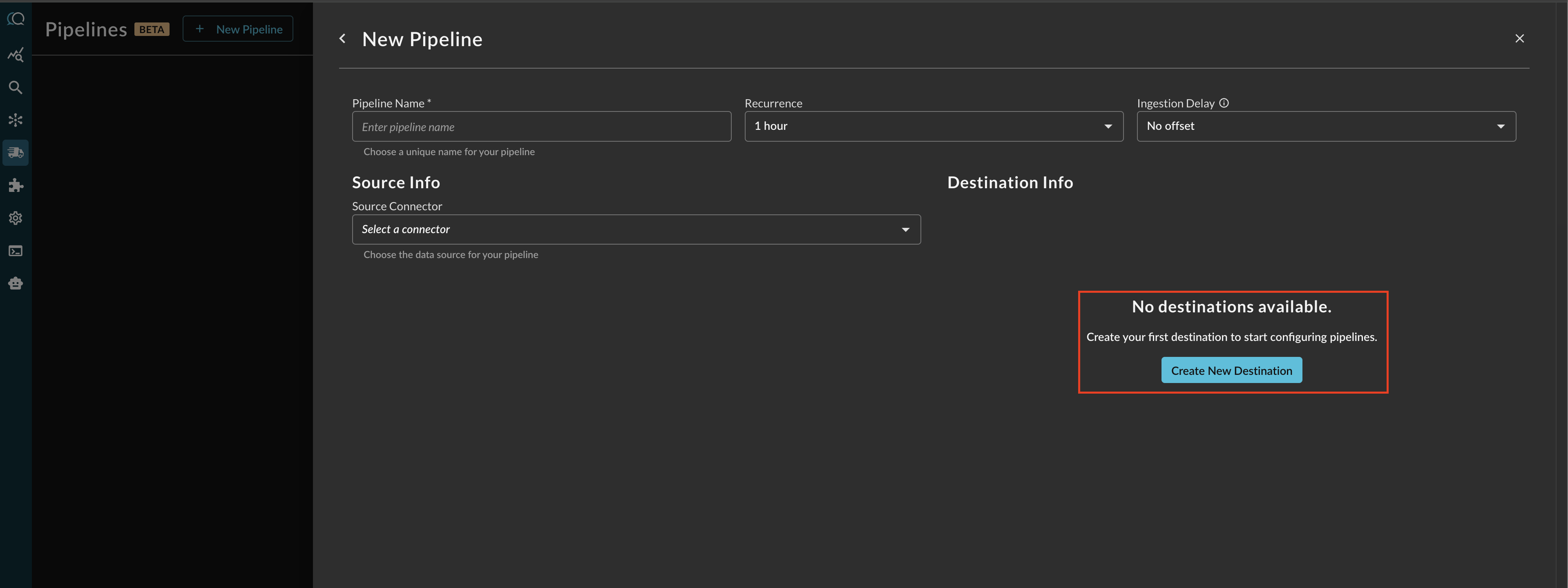
FIG. 3 - Creating a new Destination from the Pipeline configuration screen
-
Provide a Destination Name, you can reuse these destinations across multiple pipelines. From Platform select
Google Cloud Storage, and provide the following parameters as shown below (FIG. 4). Once completed, select Create.-
Project ID: Your Google Cloud Project ID where you bucket lives.
-
Bucket Name: The Bucket you want data written into.
-
Service Account JSON: The contents of the JSON Service Account Key, simply paste the entire JSON object into the field.
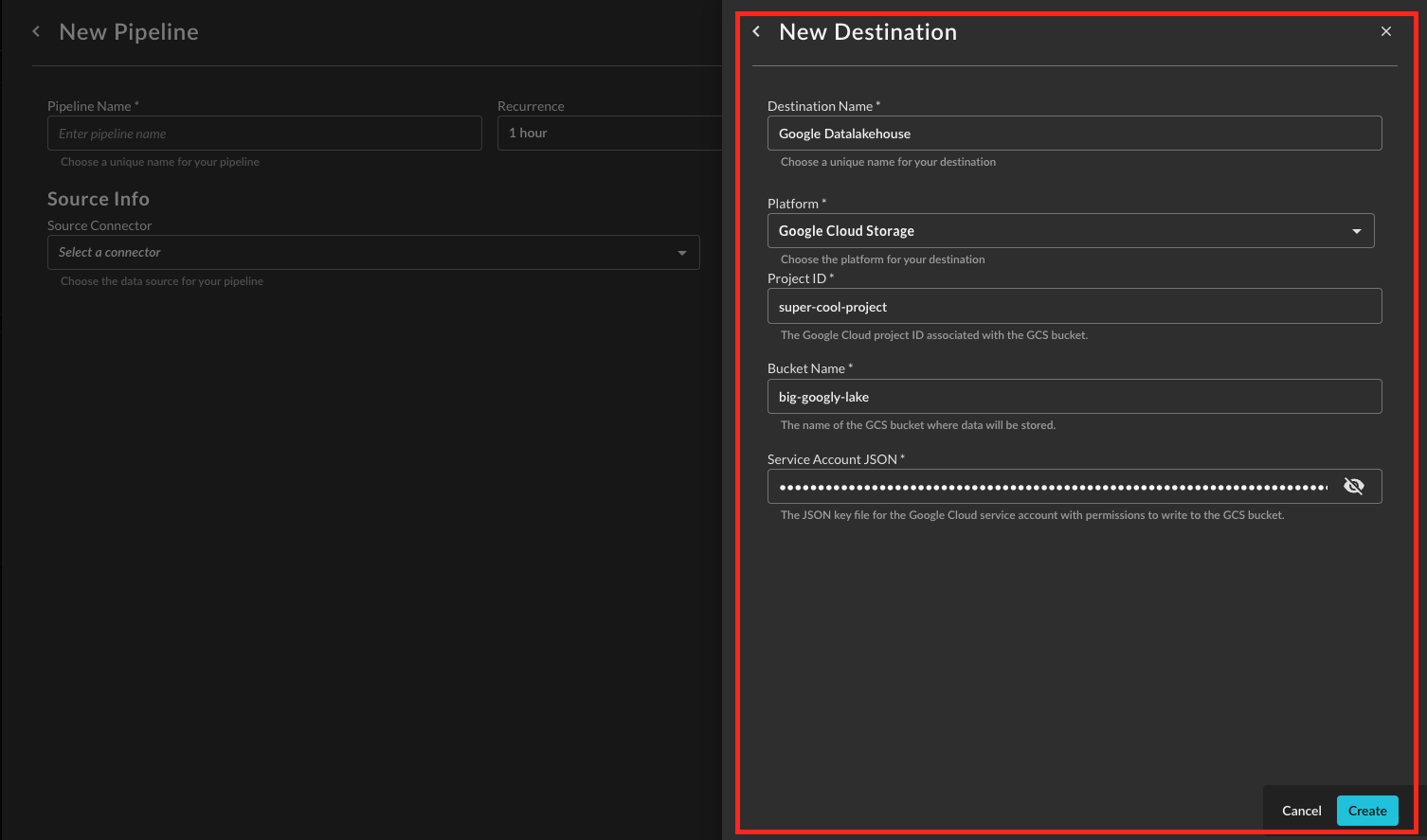
FIG. 4 - Configuring a GCS Destination
-
Operationalizing Google Cloud Storage Destinations
Query Security Data Pipelines write data to GCS in Hive-partitioned, OCSF-formatted Apache Parquet files, making it straightforward to ingest and query within Google BigQuery.
Ingesting Hive-Partitioned Data into BigQuery
To leverage the Hive-partitioned data in your GCS buckets with BigQuery, you can create an external table. This allows BigQuery to read the data directly from GCS without needing to load it into managed BigQuery storage.
- Navigate to BigQuery in Google Cloud Console: Open the BigQuery console.
- Create an External Table:
- In the navigation panel, expand your project and dataset.
- Click on
+ ADD DATA->External data source. - Configure the external table settings:
- Source Format: Select
PARQUET. - URI prefix: Enter the GCS path to your data (e.g.,
gs://your-bucket-name/source=your_connector_name/event=detection_finding/). BigQuery will use this prefix and the Hive partitioning scheme to discover your data. - Table Name: Provide a name for your BigQuery external table.
- Schema: Auto-detect the schema or manually define it.
- Partitioning and cluster settings: Enable
Hive partitioningand set thePartitioned by columnto reflect your GCS partitioning (e.g.,source,event,year,month,day,hour).
- Source Format: Select
- Click
CREATE TABLE.
For more detailed information, refer to the BigQuery documentation on Hive-partitioned loads from GCS.
Federated Search with Query's BigQuery Connector
The Query Security Data Pipelines' integration with Google BigQuery extends beyond direct ingestion. You can also utilize the Query BigQuery Connector to conduct federated searches directly on GCS-sourced data within BigQuery. This allows you to query your security data lake in GCS using BigQuery's powerful SQL capabilities without moving the data.
Updated 10 months ago