CrowdStrike Data Stored in Amazon S3
Configure CrowdStrike S3 data for Query's federated search
Data In S3
The Storing CrowdStrike FDR Data in Amazon S3 documentation guide outlines how to transfer your data from FDR to an S3 bucket.
If you already have your CrowdStrike data in an S3 bucket, this document outlines the steps to have Query's federated search platform search this data.
Data Flow
For Query to search S3 data, it first must be scanned by AWS Athena. Here's a brief architecture view:
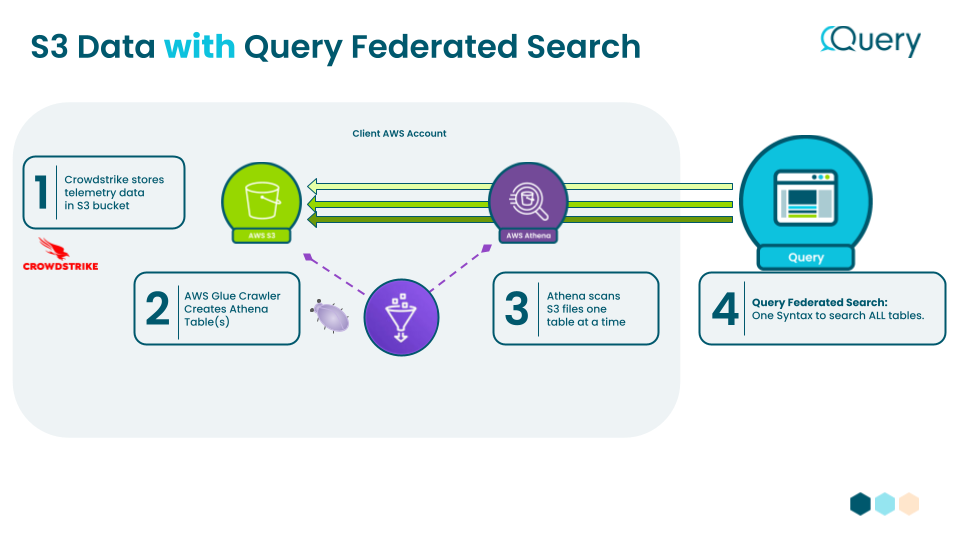
AWS Glue & Athena
If you have CrowdStrike data stored in S3, we will use AWS Glue Crawlers and Athena tables to help Query access this data.
S3 Data PartitioningYou should consider how data is structured in S3. Without a firm date type of folder structure could cause additional costs from scanning hundreds of files.
To save costs and time scanning S3 buckets, your data should be in year/month/date/ format. For example, a good folder structure could be <bucket_name/crowdstrike/year=2023/month=07/day=15. This will limit the amount of data scanned by Athena to complete the search. The more data that Athena needs to scan incurs more costs.
AWS Athena Supported Data Types
For the data to be scanned by Athena, the S3 data must be in compressed or not compressed file formats. Some common formats are:
- Parquet files
- JSON files
- JSON - line formatted
- CSV
For more information refer to AWS documentation here.
Using AWS Glue Crawlers
To get started you will need to configure an Athena table. To help with this complex configuration you may utilize AWS Glue Crawler. The Crawler will scan the data then look for common fields and create an Athena table.
For more information see the Glue/Crawler section of the Storing CrowdStrike FDR Data.
Athena
Once your AWS Glue is complete, you will see your new tables in Athena. Browse to the AWS Console Athena page and verify your tables.
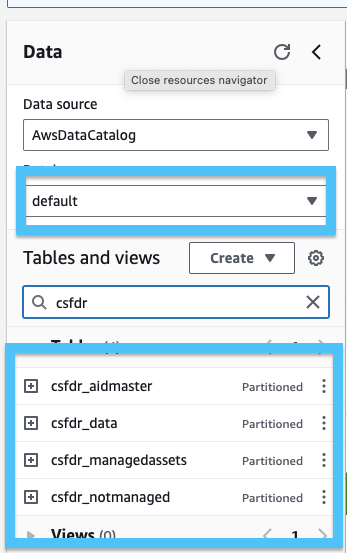
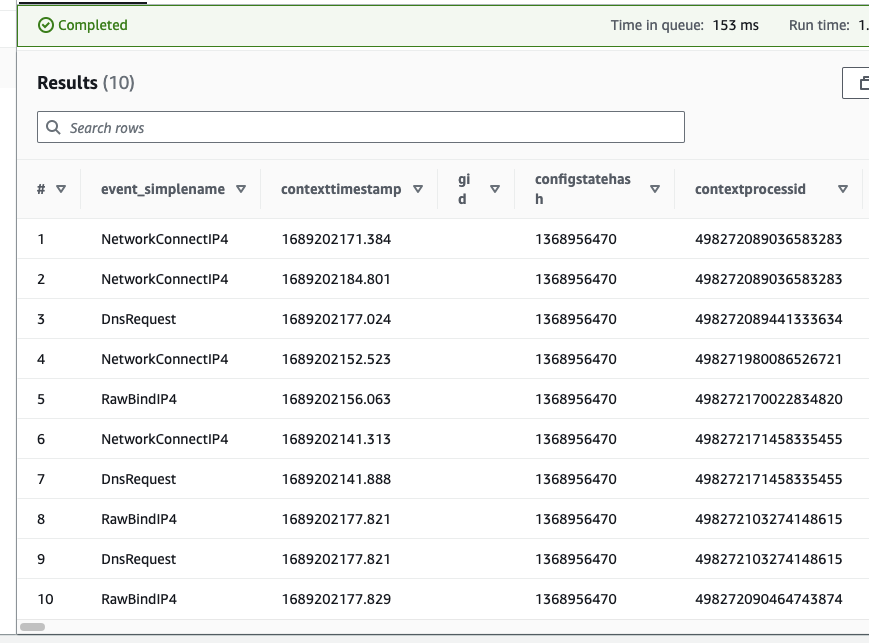
If you click the three dots next to the table name and select Preview Data, you should see your data in Athena. For example:
Configuring Query
If your data can be scanned by Athena, it is now possible to configure Query's Federated Search platform to utilize the Athena API's. Browse to the connections page of the Query app, add a new connection, and select Athena S3.

Enter the credentials. The credentials you created earlier are able to access the data.
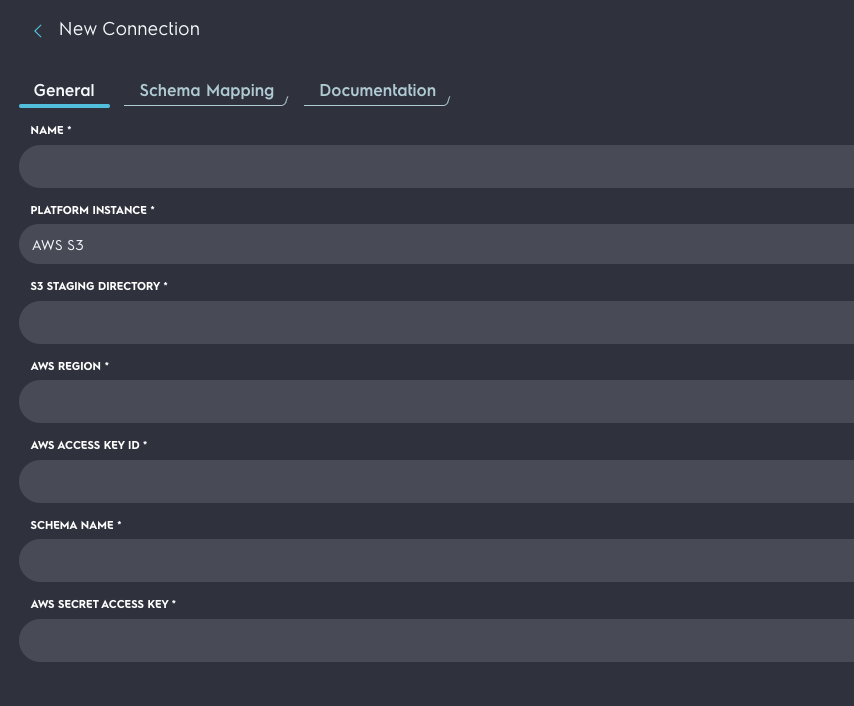
Setup the schema. For more information about setting up the schema, see the Configure Dynamic Schema's page for more information.
Updated 5 months ago